

Data Pipeline in Delta Lake
Data
Gruppe C
01/15/2022
In diesem Beitrag werden wir zunächst beschreiben, wie Delta Lake sog. Quality Levels definiert, umsetzt und wie wir diese an unseren Use-Case adaptieren.
Data Quality Levels by Delta Lake
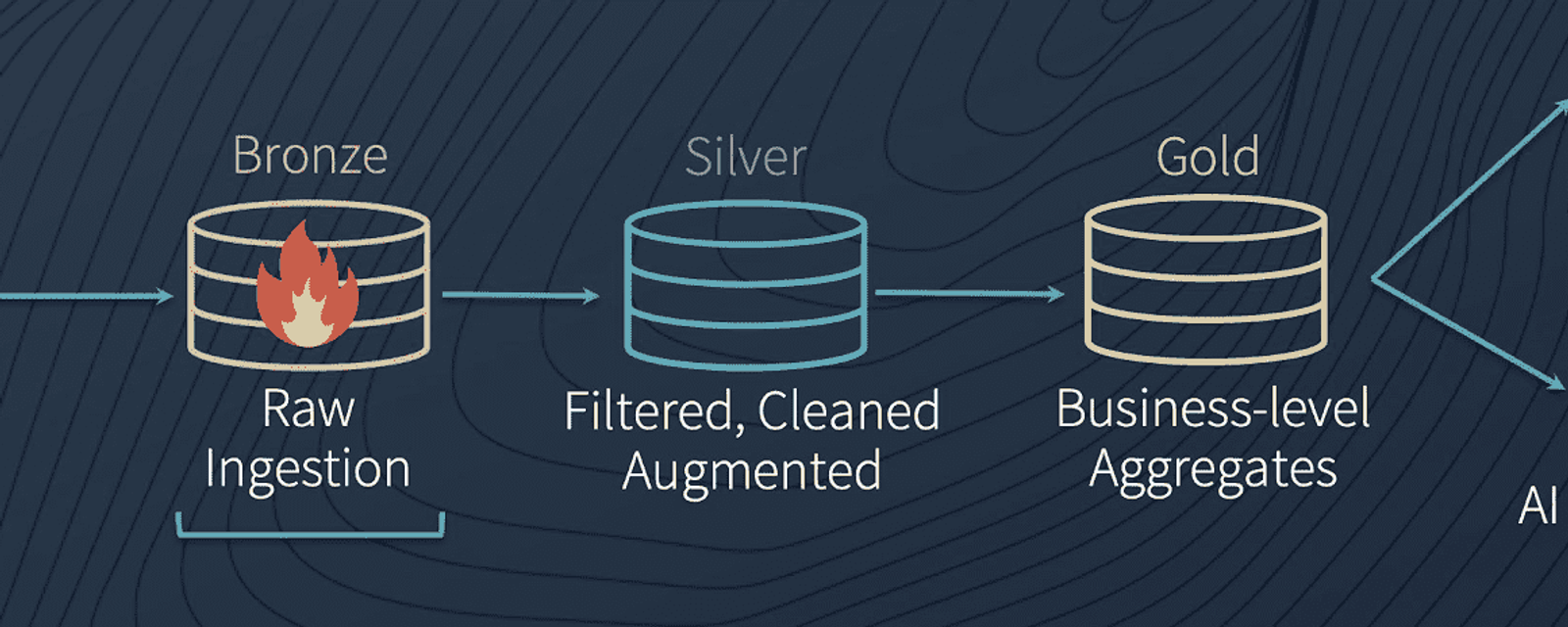
Im Allgemeinen steht im Delta Lake der „Data Flow“ im Vordergrund. Dieser soll alle Daten aus dem Unternehmen zusammenbringen, organisieren und abspeichern. Die Daten sollen so lange den „Data Flow“ durchlaufen, bis diese zur Nutzung bereit sind. Durch diesen Prozess wird die Qualität der Daten kontinuierlich verbessert. Zur Unterscheidung gibt es die sogenannten „Data Quality Levels“. Diese gibt es nicht nur im Delta Lake, sondern auch in anderen Systemen. Im Wesentlichen dienen diese zur Klassifizierung der Daten. Databricks beschreibt die Quality Levels im Delta Lake wie folgt:
- Bronze: Der Bronze-Status wird als „Dumping Ground“ für Roh-Daten bezeichnet. In diesem sollen alle Daten im Roh-Format von Anfang an erfasst und gespeichert werden. Dadurch kann auch erst später auf Daten zugegriffen werden, falls diese von neuer Bedeutung sind.
- Silver: Im Silber-Level sind die Daten noch nicht „bereit“ für die Verwendung. Allerdings wurden die Daten bereits etwas angepasst und „gecleant“. In diesem Schritt werden beispielsweise die Datei-Arten angepasst, ein Schema für die Daten festgelegt oder verschiedene Datensätze zusammengeführt.
- Gold: Im Gold Level sind die Daten bereit für die Nutzung auf Unternehmensebene. Mit diesen Daten kann eine Vielzahl an Engines verwendet werden.
Unsere Data Quality Levels
Da sich beim Aufsetzen unseres Delta Lakes gezeigt hat, dass für unseren Use-Case und die verwendeten Daten, die von Delta Lake aufgestellten Quality Levels für uns nicht ausreichend abgegrenzt sind, haben wir diese erweitert. Die von Delta Lake etablierten Level dienen lediglich als Orientierung und können noch angepasst werden.
In unserem Fall haben wir vier Quality Level und haben die drei etablierten um das Level "Platinum" ergänzt.
- Bronze: Das Bronze Level entspricht dem von Delta Lake. Hier speichern wir alle Roh-Daten, die wir aus den APIs herausbekommen, ab. Diese sind meistens CSV- oder JSON-Dateien. Dennoch wandeln wir in diesem Schritt die Daten unverändert zu Parquet-Dateien um und speichern diese für die weitere Verarbeitung zusätzlich ab.
- Silver: Hier findet bei uns die Data Augmentation statt. Die Daten werden gegebenenfalls ergänzt. Die Spotify Daten (Künstler-Daten) werden mit den Tickemaster-Daten (Konzert-Daten) zusammengeführt.
- Gold: In diesem Schritt findet bei uns das Data Cleansing statt. Separat von der Data Augmentation. Daten, die wir für unseren Use-Case nicht benötigen werden gelöscht und einzelne Zeilen oder Spalten gegebenenfalls angepasst.
- Platinum: In diesem Schritt werden unsere Daten für das Serving vorbereitet und auf den produktiven Einsatz vorbereitet. Das heißt, dass die Daten an die Machine-Learning-Engine durch beispielsweise Label Encoding, One-Hot Encoding oder Daten-Normalisierung angepasst werden.
Quellen:
Databricks. (2020a, März 4). Data Reliability for Data Lakes [Vorlesungsfolien]. https://pages.databricks.com/rs/094-YMS-629/images/Making-Apache-Spark-Better-with-Delta-Lake.pdf.
Databricks. (2020b, 15. September). Making Apache SparkTM Better with Delta Lake [Video]. YouTube. https://www.youtube.com/watch?v=LJtShrQqYZY [Stand: 02.02.2022].