

Unser Modell
Model
Sebastian
01/22/2022
1. Ansatz: Matrixfaktorisierung
Ursprünglich war für dieses Projekt als Machine Learning Modell ein klassisches Recommender System geplant. Mittels Matrixfaktorisierung sollte eine dünnbesetzte Matrix aus Konzerten und User mit einem Score oder Boolean befüllt werden. Dies erwies sich aus verschiedenen Gründen als nicht sinnvoll:
Unsere Daten sind für ein Recommender System nicht ausgelegt. Betrachtet man beispielsweise den Datensatz des Netflix Preises, sieht man, dass der Datensatz zusammenhängend ist. Sprich, jede Bewertung eines Filmes ist auf einen Netflix-User zurückzuführen. Wir in unserem Spotify Projekt hingegen, haben Daten aus zwei unterschiedlichen Quellen: Ticketmaster und Spotify. Man könnte zwar eine Matrix aus User und gehörten Liedern aus der Spotify API erstellen. Jedoch bleibt die Frage offen, wie diese auf die Konzerte überführt werden sollte, da die meisten Konzerte nicht in der Matrix enthalten wären. Dies ist auch dem geschuldet, dass die resultierende Matrix relativ klein ausgefallen wäre. Der Matrixfaktoriserungsansatz wäre möglich gewesen, hätte man ein sehr großes Pool an Künstler und User zu Verfügung.
2. Ansatz: Genre-Übereinstimmung mit Schnittmengenberechnung (Jaccard)
Sowohl die Userdaten als auch die Konzertdaten beinhalten Genreinformationen. Die Genres des Users setzen sich aus den Top 50 meistgehörten Künstlern zusammen. Die Ticketmaster Konzertdaten wurden mit Spotify API Daten bereichert und haben somit auch Genreinformationen. Mit solch einem Datensatz könnte man Konzerte und User gegenüber aufstellen und schauen, welche Konzerte die größte Übereinstimmung mit einem User, anhand der gehörten Genres haben. Die Konzerte mit der höchsten Übereinstimmung, wären dem User schließlich vorgeschlagen worden.
Während der Jaccard Koeffizient in vielen Machine Learning Bereichen Einsatz findet (z.B. Bei Computer Vision), ist es im weitesten Sinne dennoch kein Machine Learning, welches im Widerspruch zum Modul steht. Zusätzlich hätten wir Probleme mit TFX antizipieren müssen, da dieser vor allem für Keras und TensorFlow-Modelle ausgelegt ist. Vor allem zentrale Komponenten wie Evaluator und Pusher hätten nicht ohne weiteres funktionieren können.
Finaler Ansatz: Random Forest
Wir haben uns schließlich dazu entschieden ein klassisches Klassifizierungsmodell anzuwenden, damit die Integration in TFX funktionieren kann. Dazu mussten wir uns jedoch Gedanken machen, wie die Klassifizierung in unserem Use Case sinnvoll umgesetzt werden kann. Im konventionellen Machine Learning wird darauf geachtet, dass sowohl die Trainingsdaten als auch die Testdaten aus der selben Verteilung (D) genommen werden. Unser Konzept arbeitet jedoch mit 2 komplett unterschiedlichen Datensets: Userdaten aus Spotify und Konzertdaten aus Ticketmaster. Hierbei stellen sich zwei zentrale Fragen:
- Wie kann man Userdaten und Konzertdaten zusammenführen und vergleichbar machen?
- Was soll klassifiziert werden und wie passt eine Klassifizierung in unsere Anwendung (Konzertempfehlung) rein?
Lösung
Ein großer Aspekt unseres Projektes ist das Augmentieren von Daten aus verschiedenen Datenquellen, um diese zu harmonisieren. Diese Datenaugmentierung soll genutzt werden, um unsere zwei Datensets auf ein einheitliches Schema mit vergleichbaren Metriken zu überführen. Zwar sind die Daten weiterhin aus unterschiedlichen Quellen, jedoch beinhalten sie nun die gleichen Informationen, die wiederum den selben Ursprung haben - Spotify. Das ermöglicht uns, dass sowohl die Konzertdaten, als auch die Userdaten theoretisch vom selben Modell verwendet werden können. Die augmentierten Features sind unter anderem 'Follower', 'Popularity' und verschiedene Charakteristiken der Musik, ('Tempo', 'Instrumentalness', 'Valence', etc..) die als Feature für das Modell-Training genutzt werden kann. Als Label benutzen wir wieder die Genres.
Unsere Umsetzung des Trainings und Deployment variiert von der Konvention. Für das Training werden ausschließlich die Konzertdaten verwendet. Das Modell wird darauf trainiert, Genres anhand der oben aufgeführten Spotify Informationen zu prognostizieren.
Das fertiggestellte Modell wird schließlich auf die Userdaten angewandt, die die gleichen Spotify Metriken, wie die Konzertdaten verwendet.
Unsere Herangehensweise hat durchaus seine Grenzen. Zum Beispiel muss aus den Top 50 Künstlern je User aggregierte Metriken erstellt werden, welche als Feature oder Label genutzt werden. So wird als Label für den User das Genre genommen, welches am häufigsten in den 50 Künstlern auftaucht. Bei numerischen Werten wird repräsentativ ein Mittelwert benutzt. Das ist insofern problematisch, da ein User beispielsweise viel langsame Musik hört und viel schnelle Musik hört. Abstrahiert man diese Information auf den Mittelwert, wird der Eindruck erweckt, dass dieser User mittlere Tempo bevorzugt, welches vom ML-Algorithmus als solches auch interpretiert wird. Dennoch können diese Metriken auf Tendenzen eines Users hindeuten, wovon präferierte Genres abgeleitet werden können.
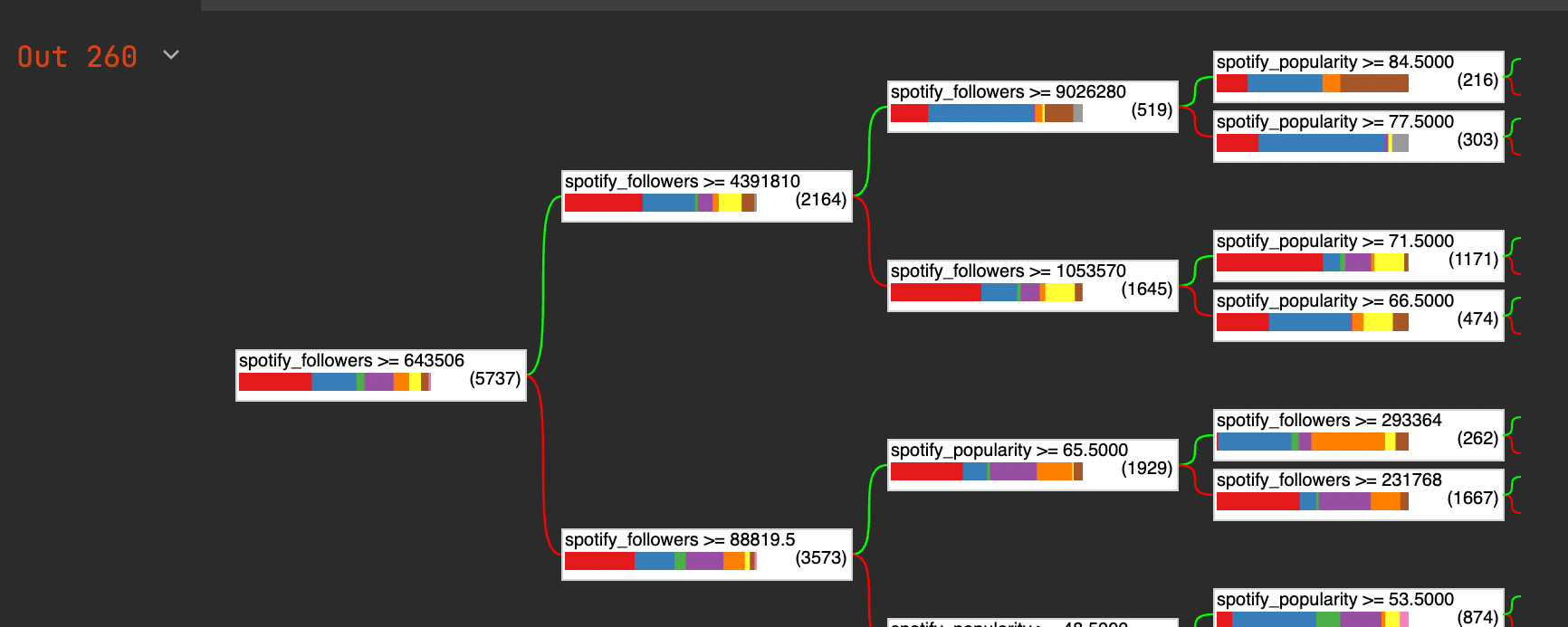
Als nächstes musste noch der Klassifizierungsalgorithmus gewählt werden. Wir haben uns dagegen entschieden ein Deep Learning Modell zu nehmen, da wir (vor allem in der ersten Iteration) sehr wenig Features hatten. Stattdessen haben wir für uns für einen Entscheidungsbaum entschieden, den Random Forest.
Sonstige Anmerkungen
Unsere Planänderungen im Projektverlauf bezüglich der Modellwahl, haben den Sinn des Delta Lakes verdeutlicht. Da unsere augmentierten Daten schon länger im Delta Lake lagen, konnten wir stehts auf bereits vorhandene Tabellen zugreifen und unsere Anpassungen ab diesem vornehmen.